
Mpi ( message passing interface )
Table of Contents
- What is MPI?
- Environment Management Routines
- Point to Point Communication Routines
- Collective Communication Routines
- Derived Data Types
- Group and Communicator Management Routines
- Virtual Topologies
- A Brief Word on MPI-2
- LLNL Specific Information and Recommendations
- References and More Information
- Appendix A: MPI-1 Routine Index
- Exercise
| What is MPI? |
![]() An Interface Specification:
An Interface Specification: 
- M P I = Message Passing Interface
- MPI is a specification for the developers and users of message passing libraries. By itself, it is NOT a library - but rather the specification of what such a library should be.
- Simply stated, the goal of the Message Passing Interface is to provide a widely used standard for writing message passing programs. The interface attempts to be
- practical
- portable
- efficient
- flexible
- Interface specifications have been defined for C/C++ and Fortran programs.
![]() The Message Passing Interface Standard (MPI) is a message passing library standard based on the consensus of the MPI Forum, which has over 40 participating organizations, including vendors, researchers, software library developers, and users. The goal of the Message Passing Interface is to establish a portable, efficient, and flexible standard for message passing that will be widely used for writing message passing programs. As such, MPI is the first standardized, vendor independent, message passing library. The advantages of developing message passing software using MPI closely match the design goals of portability, efficiency, and flexibility. MPI is not an IEEE or ISO standard, but has in fact, become the "industry standard" for writing message passing programs on HPC platforms.
The Message Passing Interface Standard (MPI) is a message passing library standard based on the consensus of the MPI Forum, which has over 40 participating organizations, including vendors, researchers, software library developers, and users. The goal of the Message Passing Interface is to establish a portable, efficient, and flexible standard for message passing that will be widely used for writing message passing programs. As such, MPI is the first standardized, vendor independent, message passing library. The advantages of developing message passing software using MPI closely match the design goals of portability, efficiency, and flexibility. MPI is not an IEEE or ISO standard, but has in fact, become the "industry standard" for writing message passing programs on HPC platforms.
The goal of this tutorial is to teach those unfamiliar with MPI how to develop and run parallel programs according to the MPI standard. The primary topics that are presented focus on those which are the most useful for new MPI programmers. The tutorial begins with an introduction, background, and basic information for getting started with MPI. This is followed by a detailed look at the MPI routines that are most useful for new MPI programmers, including MPI Environment Management, Point-to-Point Communications, and Collective Communications routines. Numerous examples in both C and Fortran are provided, as well as a lab exercise.
The tutorial materials also include more advanced topics such as Derived Data Types, Group and Communicator Management Routines, and Virtual Topologies. However, these are not actually presented during the lecture, but are meant to serve as "further reading" for those who are interested.
Level/Prerequisites: Ideal for those who are new to parallel programming with MPI. A basic understanding of parallel programming in C or Fortran is assumed. For those who are unfamiliar with Parallel Programming in general, the material covered in https://computing.llnl.gov/tutorials/parallel_comp/ would be helpful.
![]() History and Evolution:
History and Evolution:
- MPI resulted from the efforts of numerous individuals and groups over the course of a 2 year period between 1992 and 1994. Some history:
- 1980s - early 1990s: Distributed memory, parallel computing develops, as do a number of incompatible software tools for writing such programs - usually with tradeoffs between portability, performance, functionality and price. Recognition of the need for a standard arose.
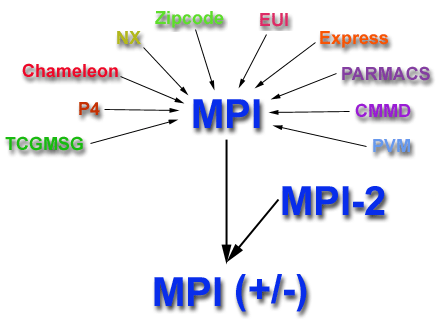
- April, 1992: Workshop on Standards for Message Passing in a Distributed Memory Environment, sponsored by the Center for Research on Parallel Computing, Williamsburg, Virginia. The basic features essential to a standard message passing interface were discussed, and a working group established to continue the standardization process. Preliminary draft proposal developed subsequently.
- November 1992: - Working group meets in Minneapolis. MPI draft proposal (MPI1) from ORNL presented. Group adopts procedures and organization to form the MPI Forum. MPIF eventually comprised of about 175 individuals from 40 organizations including parallel computer vendors, software writers, academia and application scientists.
- November 1993: Supercomputing 93 conference - draft MPI standard presented.
- MPI-2 picked up where the first MPI specification left off, and addressed topics which go beyond the first MPI specification. The original MPI then became known as MPI-1. MPI-2 is briefly covered later. Was finalized in 1996.
- Today, MPI implementations are a combination of MPI-1 and MPI-2. A few implementations include the full functionality of both.
![]() Reasons for Using MPI:
Reasons for Using MPI:
- Standardization - MPI is the only message passing library which can be considered a standard. It is supported on virtually all HPC platforms. Practically, it has replaced all previous message passing libraries.
- Portability - There is no need to modify your source code when you port your application to a different platform that supports (and is compliant with) the MPI standard.
- Performance Opportunities - Vendor implementations should be able to exploit native hardware features to optimize performance. For more information about MPI performance see the MPI Performance Topics - http://www.llnl.gov/computing/tutorials/mpi_performance tutorial.
- Functionality - Over 115 routines are defined.
- Availability - A variety of implementations are available, both vendor and public domain.
![]() Programming Model:
Programming Model:
- MPI lends itself to most (if not all) distributed memory parallel programming models. In addition, MPI is commonly used to implement (behind the scenes) some shared memory models, such as Data Parallel, on distributed memory architectures.
- Hardware platforms:
- Distributed Memory: Originally, MPI was targeted for distributed memory systems.
- Shared Memory: As shared memory systems became more popular, particularly SMP / NUMA architectures, MPI implementations for these platforms appeared.
- Hybrid: MPI is now used on just about any common parallel architecture including massively parallel machines, SMP clusters, workstation clusters and heterogeneous networks.
- All parallelism is explicit: the programmer is responsible for correctly identifying parallelism and implementing parallel algorithms using MPI constructs.
- The number of tasks dedicated to run a parallel program is static. New tasks can not be dynamically spawned during run time. (MPI-2 addresses this issue).
| Getting Started |
![]() Header File:
Header File:
- Required for all programs/routines which make MPI library calls.
C include file Fortran include file
![]() Format of MPI Calls:
Format of MPI Calls:
- C names are case sensitive; Fortran names are not.
| C Binding | |
|---|---|
| Format: | |
| Example: | |
| Error code: | Returned as "rc". MPI_SUCCESS if successful |
| Fortran Binding | |
|---|---|
| Format: | call mpi_xxxxx(parameter,..., ierr) |
| Example: | |
| Error code: | Returned as "ierr" parameter. MPI_SUCCESS if successful |
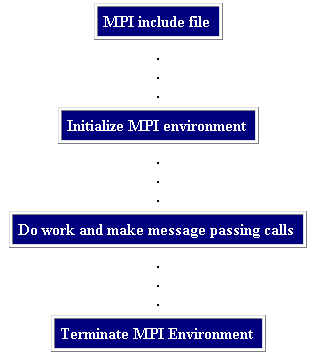
![]() General MPI Program Structure:
General MPI Program Structure:
 |
![]() Communicators and Groups:
Communicators and Groups:
-
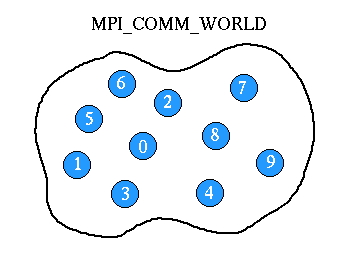
MPI uses objects called communicators and groups to define which collection of processes may communicate with each other. Most MPI routines require you to specify a communicator as an argument.
- Communicators and groups will be covered in more detail later. For now, simply use MPI_COMM_WORLD whenever a communicator is required - it is the predefined communicator that includes all of your MPI processes.
![]() Rank:
Rank:
- Within a communicator, every process has its own unique, integer identifier assigned by the system when the process initializes. A rank is sometimes also called a "process ID". Ranks are contiguous and begin at zero.
- Used by the programmer to specify the source and destination of messages. Often used conditionally by the application to control program execution (if rank=0 do this / if rank=1 do that).
| Environment Management Routines |
MPI environment management routines are used for an assortment of purposes, such as initializing and terminating the MPI environment, querying the environment and identity, etc. Most of the commonly used ones are described below.
- MPI_Init
- Initializes the MPI execution environment. This function must be called in every MPI program, must be called before any other MPI functions and must be called only once in an MPI program. For C programs, MPI_Init may be used to pass the command line arguments to all processes, although this is not required by the standard and is implementation dependent.
MPI_Init (&argc,&argv)
MPI_INIT (ierr) - MPI_Comm_size
- Determines the number of processes in the group associated with a communicator. Generally used within the communicator MPI_COMM_WORLD to determine the number of processes being used by your application.
MPI_Comm_size (comm,&size)
MPI_COMM_SIZE (comm,size,ierr) - MPI_Comm_rank
- Determines the rank of the calling process within the communicator. Initially, each process will be assigned a unique integer rank between 0 and number of processors - 1 within the communicator MPI_COMM_WORLD. This rank is often referred to as a task ID. If a process becomes associated with other communicators, it will have a unique rank within each of these as well.
MPI_Comm_rank (comm,&rank)
MPI_COMM_RANK (comm,rank,ierr) - MPI_Abort
- Terminates all MPI processes associated with the communicator. In most MPI implementations it terminates ALL processes regardless of the communicator specified.
MPI_Abort (comm,errorcode)
MPI_ABORT (comm,errorcode,ierr) - MPI_Get_processor_name
- Returns the processor name. Also returns the length of the name. The buffer for "name" must be at least MPI_MAX_PROCESSOR_NAME characters in size. What is returned into "name" is implementation dependent - may not be the same as the output of the "hostname" or "host" shell commands.
MPI_Get_processor_name (&name,&resultlength)
MPI_GET_PROCESSOR_NAME (name,resultlength,ierr) - MPI_Initialized
- Indicates whether MPI_Init has been called - returns flag as either logical true (1) or false(0). MPI requires that MPI_Init be called once and only once by each process. This may pose a problem for modules that want to use MPI and are prepared to call MPI_Init if necessary. MPI_Initialized solves this problem.
MPI_Initialized (&flag)
MPI_INITIALIZED (flag,ierr) - MPI_Wtime
- Returns an elapsed wall clock time in seconds (double precision) on the calling processor.
MPI_Wtime ()
MPI_WTIME () - MPI_Wtick
- Returns the resolution in seconds (double precision) of MPI_Wtime.
MPI_Wtick ()
MPI_WTICK () - MPI_Finalize
- Terminates the MPI execution environment. This function should be the last MPI routine called in every MPI program - no other MPI routines may be called after it.
MPI_Finalize ()
MPI_FINALIZE (ierr)
Examples: Environment Management Routines
#include "mpi.h"
#include <stdio.h>
int main(argc,argv)
int argc;
char *argv[]; {
int numtasks, rank, rc;
rc = MPI_Init(&argc,&argv);
if (rc != MPI_SUCCESS) {
printf ("Error starting MPI program. Terminating.\n");
MPI_Abort(MPI_COMM_WORLD, rc);
}
MPI_Comm_size(MPI_COMM_WORLD,&numtasks);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
printf ("Number of tasks= %d My rank= %d\n", numtasks,rank);
/******* do some work *******/
MPI_Finalize();
}
|
program simple
include 'mpif.h'
integer numtasks, rank, ierr, rc
call MPI_INIT(ierr)
if (ierr .ne. MPI_SUCCESS) then
print *,'Error starting MPI program. Terminating.'
call MPI_ABORT(MPI_COMM_WORLD, rc, ierr)
end if
call MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, numtasks, ierr)
print *, 'Number of tasks=',numtasks,' My rank=',rank
C ****** do some work ******
call MPI_FINALIZE(ierr)
end
|
| Point to Point Communication Routines |
General Concepts
- MPI point-to-point operations typically involve message passing between two, and only two, different MPI tasks. One task is performing a send operation and the other task is performing a matching receive operation.
- There are different types of send and receive routines used for different purposes. For example:
- Synchronous send
- Blocking send / blocking receive
- Non-blocking send / non-blocking receive
- Buffered send
- Combined send/receive
- "Ready" send
- Any type of send routine can be paired with any type of receive routine.
- MPI also provides several routines associated with send - receive operations, such as those used to wait for a message's arrival or probe to find out if a message has arrived.
- In a perfect world, every send operation would be perfectly synchronized with its matching receive. This is rarely the case. Somehow or other, the MPI implementation must be able to deal with storing data when the two tasks are out of sync.
- Consider the following two cases:
- A send operation occurs 5 seconds before the receive is ready - where is the message while the receive is pending?
- Multiple sends arrive at the same receiving task which can only accept one send at a time - what happens to the messages that are "backing up"?
- The MPI implementation (not the MPI standard) decides what happens to data in these types of cases. Typically, a system buffer area is reserved to hold data in transit. For example:
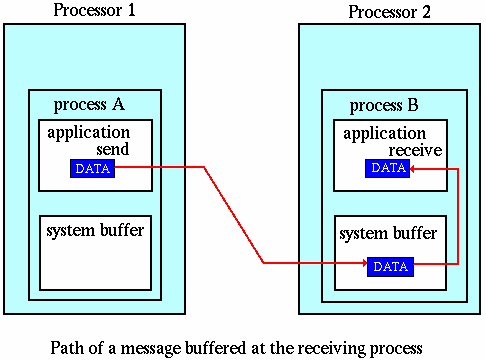
- System buffer space is:
- Opaque to the programmer and managed entirely by the MPI library
- A finite resource that can be easy to exhaust
- Often mysterious and not well documented
- Able to exist on the sending side, the receiving side, or both
- Something that may improve program performance because it allows send - receive operations to be asynchronous.
- User managed address space (i.e. your program variables) is called the application buffer. MPI also provides for a user managed send buffer.
- Most of the MPI point-to-point routines can be used in either blocking or non-blocking mode.
- Blocking:
- A blocking send routine will only "return" after it is safe to modify the application buffer (your send data) for reuse. Safe means that modifications will not affect the data intended for the receive task. Safe does not imply that the data was actually received - it may very well be sitting in a system buffer.
- A blocking send can be synchronous which means there is handshaking occurring with the receive task to confirm a safe send.
- A blocking send can be asynchronous if a system buffer is used to hold the data for eventual delivery to the receive.
- A blocking receive only "returns" after the data has arrived and is ready for use by the program.
- Non-blocking:
- Non-blocking send and receive routines behave similarly - they will return almost immediately. They do not wait for any communication events to complete, such as message copying from user memory to system buffer space or the actual arrival of message.
- Non-blocking operations simply "request" the MPI library to perform the operation when it is able. The user can not predict when that will happen.
- It is unsafe to modify the application buffer (your variable space) until you know for a fact the requested non-blocking operation was actually performed by the library. There are "wait" routines used to do this.
- Non-blocking communications are primarily used to overlap computation with communication and exploit possible performance gains.
![]() Order and Fairness:
Order and Fairness:
- Order:
- MPI guarantees that messages will not overtake each other.
- If a sender sends two messages (Message 1 and Message 2) in succession to the same destination, and both match the same receive, the receive operation will receive Message 1 before Message 2.
- If a receiver posts two receives (Receive 1 and Receive 2), in succession, and both are looking for the same message, Receive 1 will receive the message before Receive 2.
- Order rules do not apply if there are multiple threads participating in the communication operations.
- Fairness:
- MPI does not guarantee fairness - it's up to the programmer to prevent "operation starvation".
- Example: task 0 sends a message to task 2. However, task 1 sends a competing message that matches task 2's receive. Only one of the sends will complete.
| Point to Point Communication Routines |
MPI Message Passing Routine Arguments
MPI point-to-point communication routines generally have an argument list that takes one of the following formats:
| Blocking sends | |
| Non-blocking sends | |
| Blocking receive | |
| Non-blocking receive |
- Buffer
- Program (application) address space that references the data that is to be sent or received. In most cases, this is simply the variable name that is be sent/received. For C programs, this argument is passed by reference and usually must be prepended with an ampersand: &var1
- Data Count
- Indicates the number of data elements of a particular type to be sent.
- Data Type
- For reasons of portability, MPI predefines its elementary data types. The table below lists those required by the standard.
C Data Types Fortran Data Types signed char character(1) signed short int signed int integer signed long int unsigned char unsigned short int unsigned int unsigned long int float real double double precision long double complex double complex logical 8 binary digits 8 binary digits data packed or unpacked with MPI_Pack()/ MPI_Unpack data packed or unpacked with MPI_Pack()/ MPI_Unpack Notes:
- Programmers may also create their own data types (see Derived Data Types).
- MPI_BYTE and MPI_PACKED do not correspond to standard C or Fortran types.
- The MPI standard includes the following optional data types:
- C: MPI_LONG_LONG_INT
- Fortran: MPI_INTEGER1, MPI_INTEGER2, MPI_INTEGER4, MPI_REAL2, MPI_REAL4, MPI_REAL8
- Some implementations may include additional elementary data types (MPI_LOGICAL2, MPI_COMPLEX32, etc.). Check the MPI header file.
- Destination
- An argument to send routines that indicates the process where a message should be delivered. Specified as the rank of the receiving process.
- Source
- An argument to receive routines that indicates the originating process of the message. Specified as the rank of the sending process. This may be set to the wild card MPI_ANY_SOURCE to receive a message from any task.
- Tag
- Arbitrary non-negative integer assigned by the programmer to uniquely identify a message. Send and receive operations should match message tags. For a receive operation, the wild card MPI_ANY_TAG can be used to receive any message regardless of its tag. The MPI standard guarantees that integers 0-32767 can be used as tags, but most implementations allow a much larger range than this.
- Communicator
- Indicates the communication context, or set of processes for which the source or destination fields are valid. Unless the programmer is explicitly creating new communicators, the predefined communicator MPI_COMM_WORLD is usually used.
- Status
- For a receive operation, indicates the source of the message and the tag of the message. In C, this argument is a pointer to a predefined structure MPI_Status (ex. stat.MPI_SOURCE stat.MPI_TAG). In Fortran, it is an integer array of size MPI_STATUS_SIZE (ex. stat(MPI_SOURCE) stat(MPI_TAG)). Additionally, the actual number of bytes received are obtainable from Status via the MPI_Get_count routine.
- Request
- Used by non-blocking send and receive operations. Since non-blocking operations may return before the requested system buffer space is obtained, the system issues a unique "request number". The programmer uses this system assigned "handle" later (in a WAIT type routine) to determine completion of the non-blocking operation. In C, this argument is a pointer to a predefined structure MPI_Request. In Fortran, it is an integer.
| Point to Point Communication Routines |
Blocking Message Passing Routines
The more commonly used MPI blocking message passing routines are described below.
- MPI_Send
- Basic blocking send operation. Routine returns only after the application buffer in the sending task is free for reuse. Note that this routine may be implemented differently on different systems. The MPI standard permits the use of a system buffer but does not require it. Some implementations may actually use a synchronous send (discussed below) to implement the basic blocking send.
MPI_Send (&buf,count,datatype,dest,tag,comm)
MPI_SEND (buf,count,datatype,dest,tag,comm,ierr) - MPI_Recv
- Receive a message and block until the requested data is available in the application buffer in the receiving task.
MPI_Recv (&buf,count,datatype,source,tag,comm,&status)
MPI_RECV (buf,count,datatype,source,tag,comm,status,ierr) - MPI_Ssend
- Synchronous blocking send: Send a message and block until the application buffer in the sending task is free for reuse and the destination process has started to receive the message.
MPI_Ssend (&buf,count,datatype,dest,tag,comm)
MPI_SSEND (buf,count,datatype,dest,tag,comm,ierr) - MPI_Bsend
- Buffered blocking send: permits the programmer to allocate the required amount of buffer space into which data can be copied until it is delivered. Insulates against the problems associated with insufficient system buffer space. Routine returns after the data has been copied from application buffer space to the allocated send buffer. Must be used with the MPI_Buffer_attach routine.
MPI_Bsend (&buf,count,datatype,dest,tag,comm)
MPI_BSEND (buf,count,datatype,dest,tag,comm,ierr) - MPI_Buffer_attach
MPI_Buffer_detach - Used by programmer to allocate/deallocate message buffer space to be used by the MPI_Bsend routine. The size argument is specified in actual data bytes - not a count of data elements. Only one buffer can be attached to a process at a time. Note that the IBM implementation uses MPI_BSEND_OVERHEAD bytes of the allocated buffer for overhead.
MPI_Buffer_attach (&buffer,size)
MPI_Buffer_detach (&buffer,size)
MPI_BUFFER_ATTACH (buffer,size,ierr)
MPI_BUFFER_DETACH (buffer,size,ierr) - MPI_Rsend
- Blocking ready send. Should only be used if the programmer is certain that the matching receive has already been posted.
MPI_Rsend (&buf,count,datatype,dest,tag,comm)
MPI_RSEND (buf,count,datatype,dest,tag,comm,ierr) - MPI_Sendrecv
- Send a message and post a receive before blocking. Will block until the sending application buffer is free for reuse and until the receiving application buffer contains the received message.
MPI_Sendrecv (&sendbuf,sendcount,sendtype,dest,sendtag,
...... &recvbuf,recvcount,recvtype,source,recvtag,
...... comm,&status)
MPI_SENDRECV (sendbuf,sendcount,sendtype,dest,sendtag,
...... recvbuf,recvcount,recvtype,source,recvtag,
...... comm,status,ierr) - MPI_Wait
MPI_Waitany
MPI_Waitall
MPI_Waitsome - MPI_Wait blocks until a specified non-blocking send or receive operation has completed. For multiple non-blocking operations, the programmer can specify any, all or some completions.
MPI_Wait (&request,&status)
MPI_Waitany (count,&array_of_requests,&index,&status)
MPI_Waitall (count,&array_of_requests,&array_of_statuses)
MPI_Waitsome (incount,&array_of_requests,&outcount,
...... &array_of_offsets, &array_of_statuses)
MPI_WAIT (request,status,ierr)
MPI_WAITANY (count,array_of_requests,index,status,ierr)
MPI_WAITALL (count,array_of_requests,array_of_statuses,
...... ierr)
MPI_WAITSOME (incount,array_of_requests,outcount,
...... array_of_offsets, array_of_statuses,ierr) - MPI_Probe
- Performs a blocking test for a message. The "wildcards" MPI_ANY_SOURCE and MPI_ANY_TAG may be used to test for a message from any source or with any tag. For the C routine, the actual source and tag will be returned in the status structure as status.MPI_SOURCE and status.MPI_TAG. For the Fortran routine, they will be returned in the integer array status(MPI_SOURCE) and status(MPI_TAG).
MPI_Probe (source,tag,comm,&status)
MPI_PROBE (source,tag,comm,status,ierr)
Examples: Blocking Message Passing Routines
Task 0 pings task 1 and awaits return ping
#include "mpi.h"
#include <stdio.h>
int main(argc,argv)
int argc;
char *argv[]; {
int numtasks, rank, dest, source, rc, count, tag=1;
char inmsg, outmsg='x';
MPI_Status Stat;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD, &numtasks);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (rank == 0) {
dest = 1;
source = 1;
rc = MPI_Send(&outmsg, 1, MPI_CHAR, dest, tag, MPI_COMM_WORLD);
rc = MPI_Recv(&inmsg, 1, MPI_CHAR, source, tag, MPI_COMM_WORLD, &Stat);
}
else if (rank == 1) {
dest = 0;
source = 0;
rc = MPI_Recv(&inmsg, 1, MPI_CHAR, source, tag, MPI_COMM_WORLD, &Stat);
rc = MPI_Send(&outmsg, 1, MPI_CHAR, dest, tag, MPI_COMM_WORLD);
}
rc = MPI_Get_count(&Stat, MPI_CHAR, &count);
printf("Task %d: Received %d char(s) from task %d with tag %d \n",
rank, count, Stat.MPI_SOURCE, Stat.MPI_TAG);
MPI_Finalize();
}
|
program ping
include 'mpif.h'
integer numtasks, rank, dest, source, count, tag, ierr
integer stat(MPI_STATUS_SIZE)
character inmsg, outmsg
outmsg = 'x'
tag = 1
call MPI_INIT(ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, numtasks, ierr)
if (rank .eq. 0) then
dest = 1
source = 1
call MPI_SEND(outmsg, 1, MPI_CHARACTER, dest, tag,
& MPI_COMM_WORLD, ierr)
call MPI_RECV(inmsg, 1, MPI_CHARACTER, source, tag,
& MPI_COMM_WORLD, stat, ierr)
else if (rank .eq. 1) then
dest = 0
source = 0
call MPI_RECV(inmsg, 1, MPI_CHARACTER, source, tag,
& MPI_COMM_WORLD, stat, err)
call MPI_SEND(outmsg, 1, MPI_CHARACTER, dest, tag,
& MPI_COMM_WORLD, err)
endif
call MPI_GET_COUNT(stat, MPI_CHARACTER, count, ierr)
print *, 'Task ',rank,': Received', count, 'char(s) from task',
& stat(MPI_SOURCE), 'with tag',stat(MPI_TAG)
call MPI_FINALIZE(ierr)
end
|
| Point to Point Communication Routines |
Non-Blocking Message Passing Routines
The more commonly used MPI non-blocking message passing routines are described below.
- MPI_Isend
- Identifies an area in memory to serve as a send buffer. Processing continues immediately without waiting for the message to be copied out from the application buffer. A communication request handle is returned for handling the pending message status. The program should not modify the application buffer until subsequent calls to MPI_Wait or MPI_Test indicate that the non-blocking send has completed.
MPI_Isend (&buf,count,datatype,dest,tag,comm,&request)
MPI_ISEND (buf,count,datatype,dest,tag,comm,request,ierr) - MPI_Irecv
- Identifies an area in memory to serve as a receive buffer. Processing continues immediately without actually waiting for the message to be received and copied into the the application buffer. A communication request handle is returned for handling the pending message status. The program must use calls to MPI_Wait or MPI_Test to determine when the non-blocking receive operation completes and the requested message is available in the application buffer.
MPI_Irecv (&buf,count,datatype,source,tag,comm,&request)
MPI_IRECV (buf,count,datatype,source,tag,comm,request,ierr) - MPI_Issend
- Non-blocking synchronous send. Similar to MPI_Isend(), except MPI_Wait() or MPI_Test() indicates when the destination process has received the message.
MPI_Issend (&buf,count,datatype,dest,tag,comm,&request)
MPI_ISSEND (buf,count,datatype,dest,tag,comm,request,ierr) - MPI_Ibsend
- Non-blocking buffered send. Similar to MPI_Bsend() except MPI_Wait() or MPI_Test() indicates when the destination process has received the message. Must be used with the MPI_Buffer_attach routine.
MPI_Ibsend (&buf,count,datatype,dest,tag,comm,&request)
MPI_IBSEND (buf,count,datatype,dest,tag,comm,request,ierr) - MPI_Irsend
- Non-blocking ready send. Similar to MPI_Rsend() except MPI_Wait() or MPI_Test() indicates when the destination process has received the message. Should only be used if the programmer is certain that the matching receive has already been posted.
MPI_Irsend (&buf,count,datatype,dest,tag,comm,&request)
MPI_IRSEND (buf,count,datatype,dest,tag,comm,request,ierr) - MPI_Test
MPI_Testany
MPI_Testall
MPI_Testsome - MPI_Test checks the status of a specified non-blocking send or receive operation. The "flag" parameter is returned logical true (1) if the operation has completed, and logical false (0) if not. For multiple non-blocking operations, the programmer can specify any, all or some completions.
MPI_Test (&request,&flag,&status)
MPI_Testany (count,&array_of_requests,&index,&flag,&status)
MPI_Testall (count,&array_of_requests,&flag,&array_of_statuses)
MPI_Testsome (incount,&array_of_requests,&outcount,
...... &array_of_offsets, &array_of_statuses)
MPI_TEST (request,flag,status,ierr)
MPI_TESTANY (count,array_of_requests,index,flag,status,ierr)
MPI_TESTALL (count,array_of_requests,flag,array_of_statuses,ierr)
MPI_TESTSOME (incount,array_of_requests,outcount,
...... array_of_offsets, array_of_statuses,ierr)
- MPI_Iprobe
- Performs a non-blocking test for a message. The "wildcards" MPI_ANY_SOURCE and MPI_ANY_TAG may be used to test for a message from any source or with any tag. The integer "flag" parameter is returned logical true (1) if a message has arrived, and logical false (0) if not. For the C routine, the actual source and tag will be returned in the status structure as status.MPI_SOURCE and status.MPI_TAG. For the Fortran routine, they will be returned in the integer array status(MPI_SOURCE) and status(MPI_TAG).
MPI_Iprobe (source,tag,comm,&flag,&status)
MPI_IPROBE (source,tag,comm,flag,status,ierr)
Examples: Non-Blocking Message Passing Routines
Nearest neighbor exchange in ring topology
#include "mpi.h"
#include <stdio.h>
int main(argc,argv)
int argc;
char *argv[]; {
int numtasks, rank, next, prev, buf[2], tag1=1, tag2=2;
MPI_Request reqs[4];
MPI_Status stats[4];
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD, &numtasks);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
prev = rank-1;
next = rank+1;
if (rank == 0) prev = numtasks - 1;
if (rank == (numtasks - 1)) next = 0;
MPI_Irecv(&buf[0], 1, MPI_INT, prev, tag1, MPI_COMM_WORLD, &reqs[0]);
MPI_Irecv(&buf[1], 1, MPI_INT, next, tag2, MPI_COMM_WORLD, &reqs[1]);
MPI_Isend(&rank, 1, MPI_INT, prev, tag2, MPI_COMM_WORLD, &reqs[2]);
MPI_Isend(&rank, 1, MPI_INT, next, tag1, MPI_COMM_WORLD, &reqs[3]);
{ do some work }
MPI_Waitall(4, reqs, stats);
MPI_Finalize();
}
|
program ringtopo
include 'mpif.h'
integer numtasks, rank, next, prev, buf(2), tag1, tag2, ierr
integer stats(MPI_STATUS_SIZE,4), reqs(4)
tag1 = 1
tag2 = 2
call MPI_INIT(ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, numtasks, ierr)
prev = rank - 1
next = rank + 1
if (rank .eq. 0) then
prev = numtasks - 1
endif
if (rank .eq. numtasks - 1) then
next = 0
endif
call MPI_IRECV(buf(1), 1, MPI_INTEGER, prev, tag1,
& MPI_COMM_WORLD, reqs(1), ierr)
call MPI_IRECV(buf(2), 1, MPI_INTEGER, next, tag2,
& MPI_COMM_WORLD, reqs(2), ierr)
call MPI_ISEND(rank, 1, MPI_INTEGER, prev, tag2,
& MPI_COMM_WORLD, reqs(3), ierr)
call MPI_ISEND(rank, 1, MPI_INTEGER, next, tag1,
& MPI_COMM_WORLD, reqs(4), ierr)
C do some work
call MPI_WAITALL(4, reqs, stats, ierr);
call MPI_FINALIZE(ierr)
end
|
| Collective Communication Routines |
![]() All or None:
All or None:
- Collective communication must involve all processes in the scope of a communicator. All processes are by default, members in the communicator MPI_COMM_WORLD.
- It is the programmer's responsibility to insure that all processes within a communicator participate in any collective operations.
![]() Types of Collective Operations:
Types of Collective Operations:
- Synchronization - processes wait until all members of the group have reached the synchronization point.
- Data Movement - broadcast, scatter/gather, all to all.
- Collective Computation (reductions) - one member of the group collects data from the other members and performs an operation (min, max, add, multiply, etc.) on that data.
- Collective operations are blocking.
- Collective communication routines do not take message tag arguments.
- Collective operations within subsets of processes are accomplished by first partitioning the subsets into new groups and then attaching the new groups to new communicators (discussed in the Group and Communicator Management Routines section).
- Can only be used with MPI predefined datatypes - not with MPI Derived Data Types.
Collective Communication Routines
-
Creates a barrier synchronization in a group. Each task, when reaching the MPI_Barrier call, blocks until all tasks in the group reach the same MPI_Barrier call.
MPI_Barrier (comm)
MPI_BARRIER (comm,ierr)